About
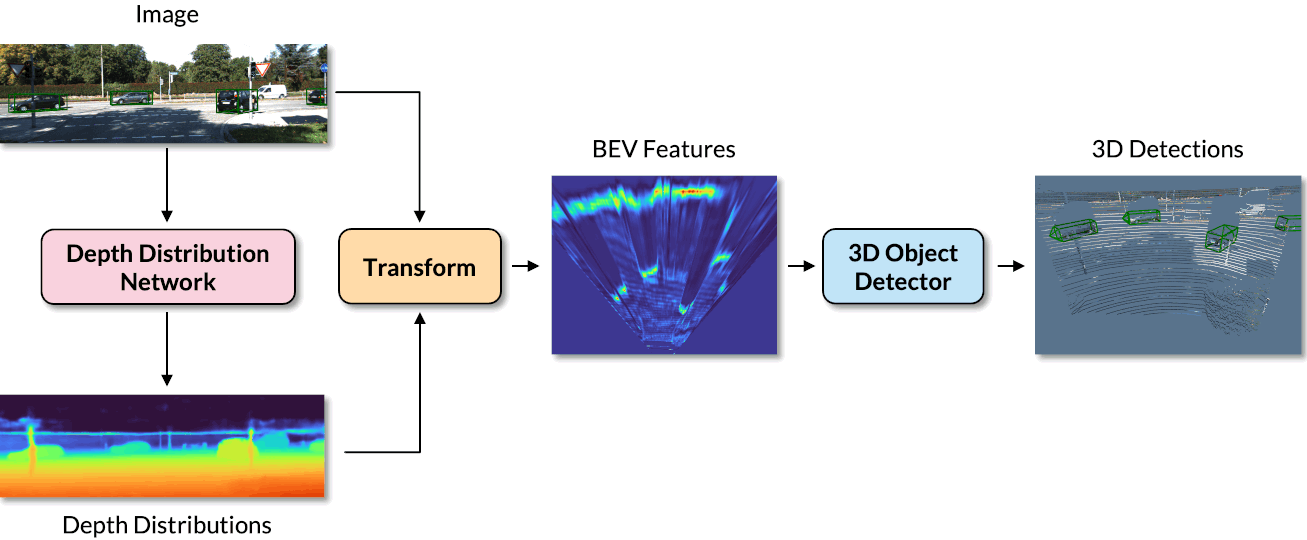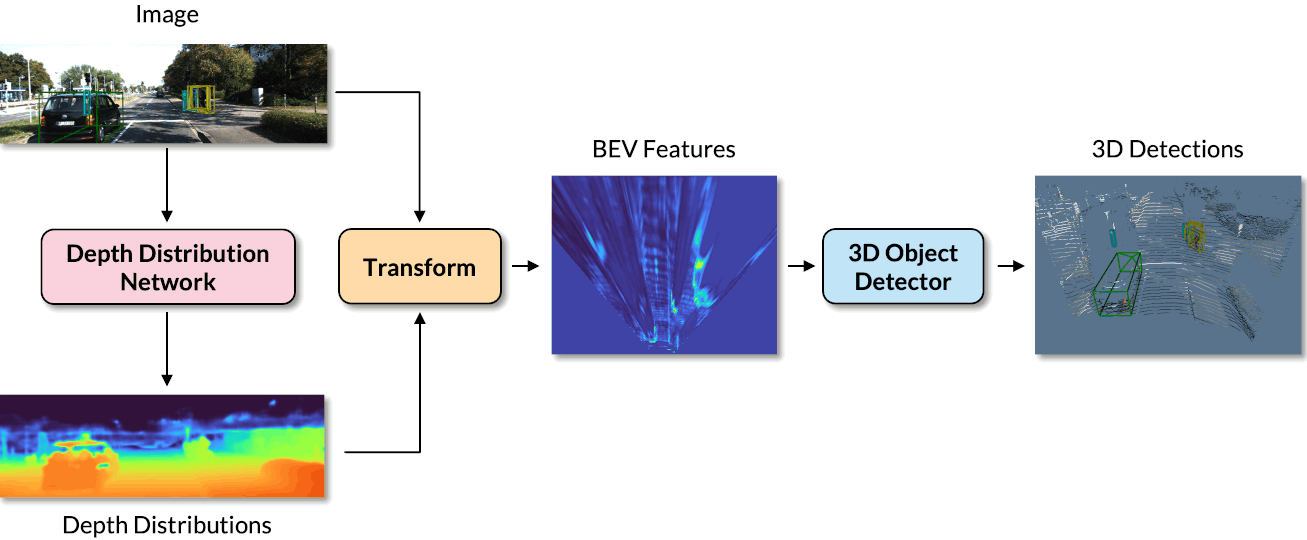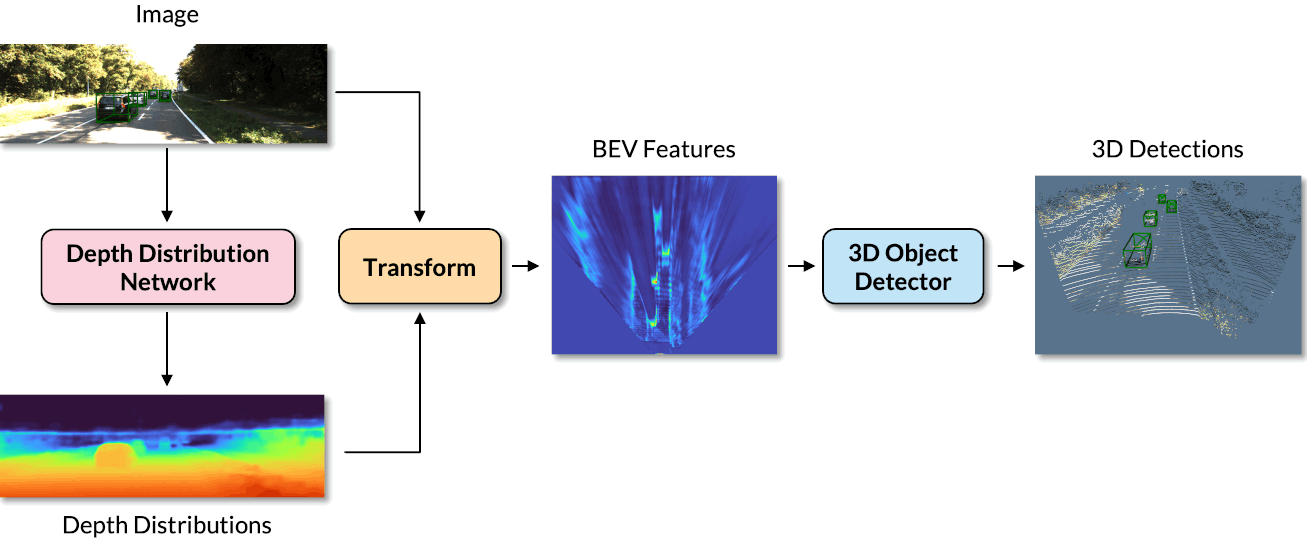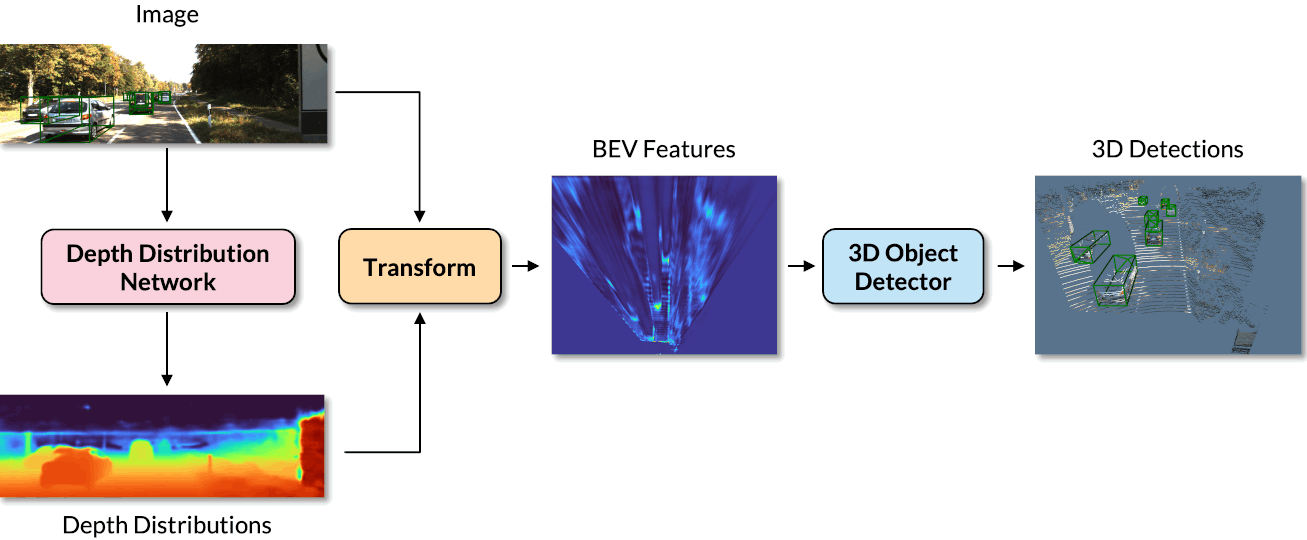
CaDDN is a monocular 3D object detection pipeline that estimates a categorical depth distribution for each pixel to project image feature information to the appropiate depth interval in 3D space. The bird’s-eye-view projection and single-stage detector are then used to produce the final output detections.
Highlights
- 1st place on KITTI 3D object detection benchmark (among published monocular methods upon time of submission)
- 1st monocular method to report results on the Waymo Open Dataset
Paper
Categorical Depth Distribution Network for Monocular 3D Object Detection
Cody Reading, Ali Harakeh, Julia Chae, and Steven L. Waslander
CVPR 2021 (Oral)
@article{CaDDN,
title={Categorical Depth Distribution Network for Monocular 3D Object Detection},
author={Cody Reading and
Ali Harakeh and
Julia Chae and
Steven L. Waslander},
journal = {CVPR},
year={2021}
}
Problem
The main problem in monocular 3D detection is the depth information loss when 3D scene information is projected onto the image plane. Without depth, accurately locating 3D objects is challenging.

Many monocular methods attempt to recover the lost depth in order to project the pixels back into 3D space. We categorize these into the Too Big and Too Small approaches.
Too Big
These approaches project each image to all possible depths, and allow the detection network to learn which projected image pixel locations are the most relevant.

Methods here tend to suffer from smearing effects, wherein similar image information can exist at multiple locations in the projected space. Smearing increases the difficulty of localizing objects in the scene.
Too Small
These approaches learn a single depth value for each pixel, and project the pixel to a single depth in 3D space.

This solution would be ideal with perfect depth information. The issue is that monocular depth estimation can be inaccurate, particulary at long range. All projected image pixels are treated equally regardless of depth estimation uncertainty, resulting in poor localization where depth estimates are inaccurate.
Our Solution
Our solution takes a Just Right approach. We project pixels to all possible depths and weigh the projection by estimated depth probabilities. The weighted projection allows CaDDN to place image information at the correct locations while encoding depth estimation uncertainty.

Specfically, CaDDN estimates categorical depth distributions for each pixel, that contain probabilities that each pixel belongs to a set of discrete depth bins. This can be thought of as performing pixel-wise classification between depth bins, where the classification probabilities are then used as multplicative weights during projection.
Architecture
The full architecture of CaDDN is as follows:

The network is composed of three modules to generate 3D feature representations and one to perform 3D detection. Frustum features G are generated from an image I using estimated depth distributions D, which are transformed into voxel features V. The voxel features are collapsed to bird’s-eye-view features B to be used for 3D object detection
Frustum Feature Network
To generate frustum features G, image features F and depth distributions D are predicted in parallel using convolutional networks. These are combined via an outer product, which multiplies each feature pixel by its associated depth bin probabilities. By doing so, the image features are projcted into a 3D frustum grid.

Frustum to Voxel Transformation
The frustum features G are transformed to a voxel representation V, leveraging known camera calibration and differentiable sampling. Sampling points in each voxel in V are projected into the frustum grid using the camera calibration matrix. Frustum features are sampled using trilinear interpolation (shown as blue in G) to populate voxels in V.

Voxel Collapse
The voxel grid V is collapsed into a BEV grid B. The height axis of V is concatenated along the channel axis, followed by a channel reduction layer with 1x1 convolutions to retrieve the original number of feature channels. The voxel collapse module acts as a learned collapse module to generate the BEV grid B.
3D Object Detector
3D object detection is performed using a BEV detection network. Specifically, the backbone and detection head from PointPillars are used to generate the bounding box estimations.
Results
3D Detection Peformance
CaDDN achieve state-of-the-art performance on both the KITTI and Waymo datasets.
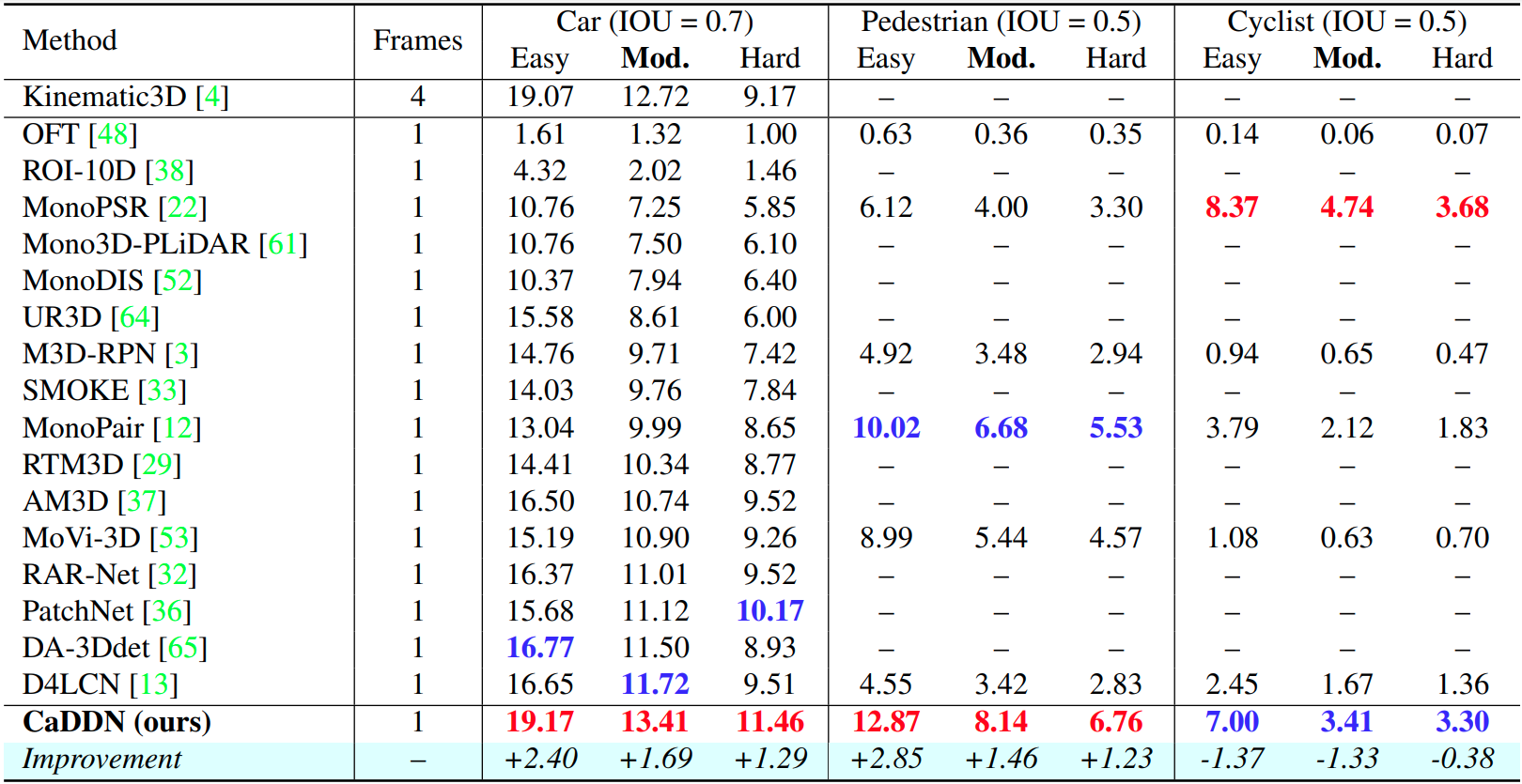
We show the 3D detection results on the KITTI test set, using the AP|R40 metric. We indicate the highest result with red and the second highest with blue. Full results for CaDDN be accessed here.
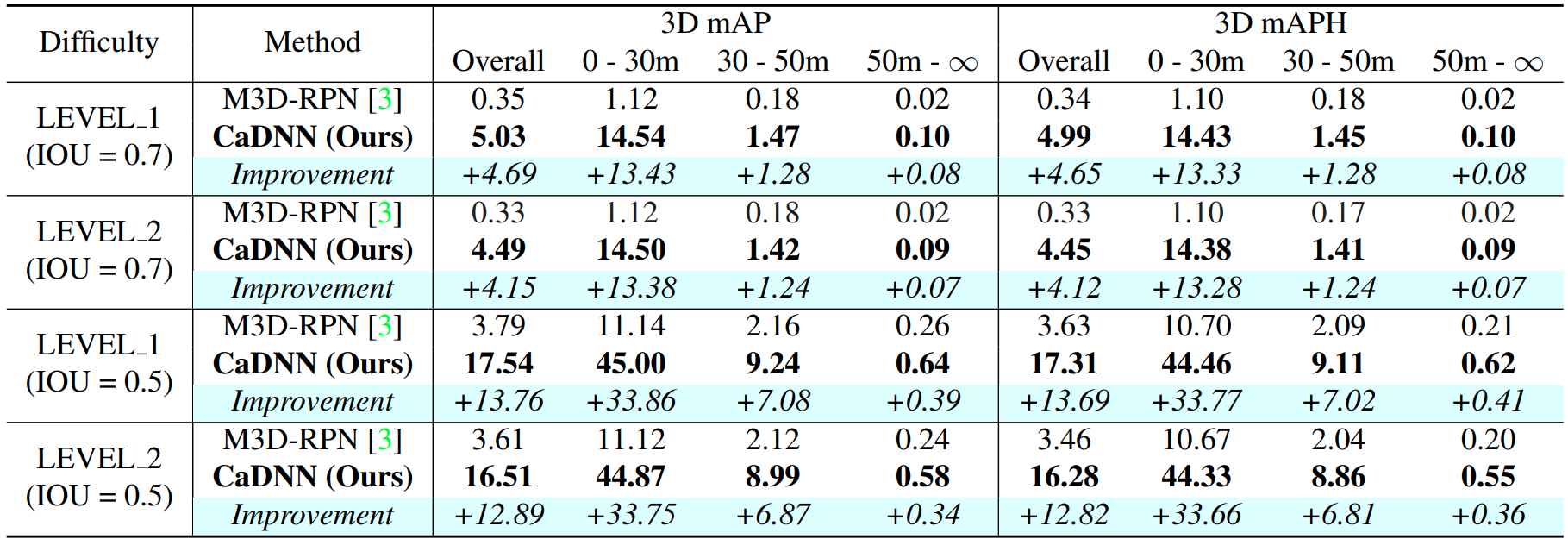
We also show the 3D detection results on the Waymo validation set on the Vehicle class. We evaluate M3D-RPM as a baseline for comparison.
Visualizations
We can also visualize the various representations produced from our network.
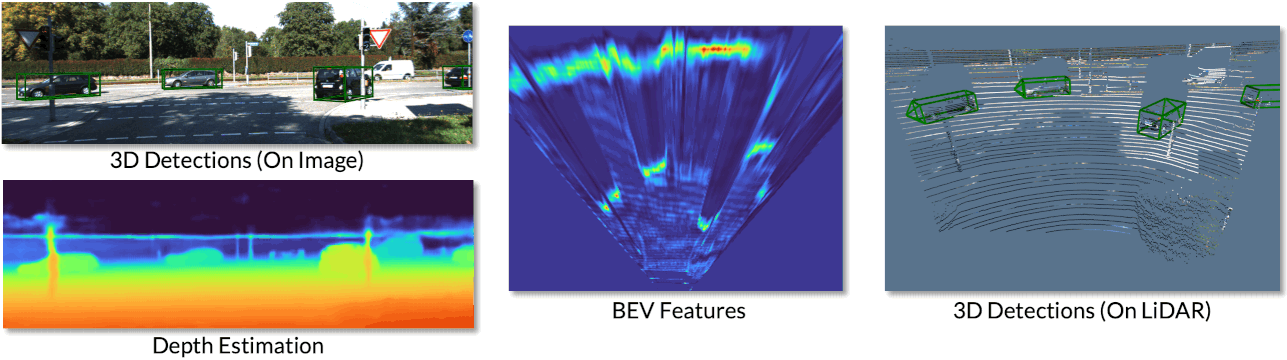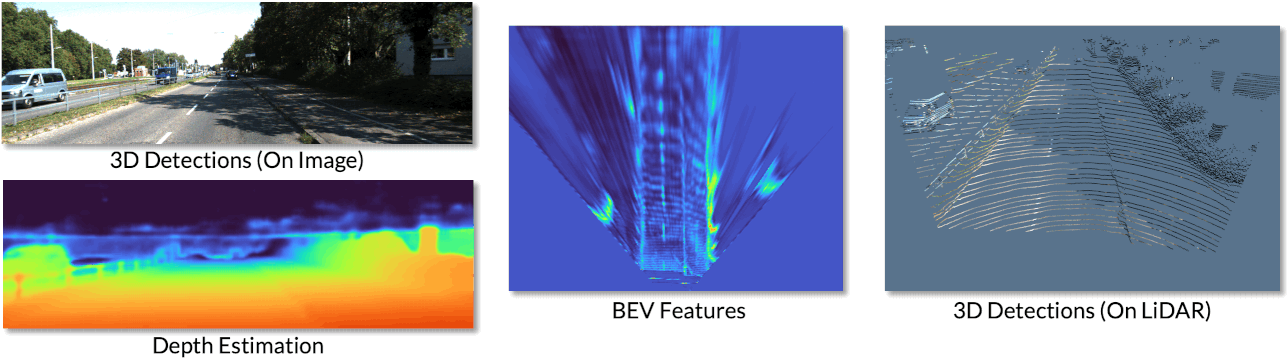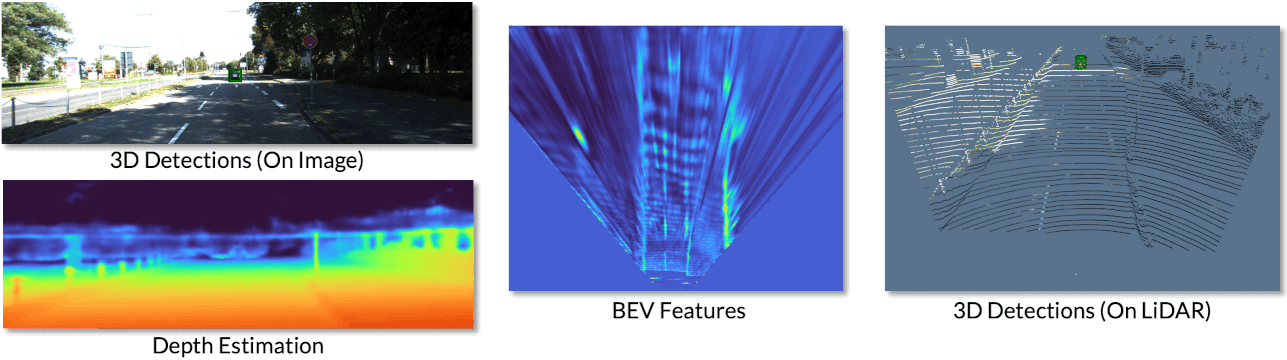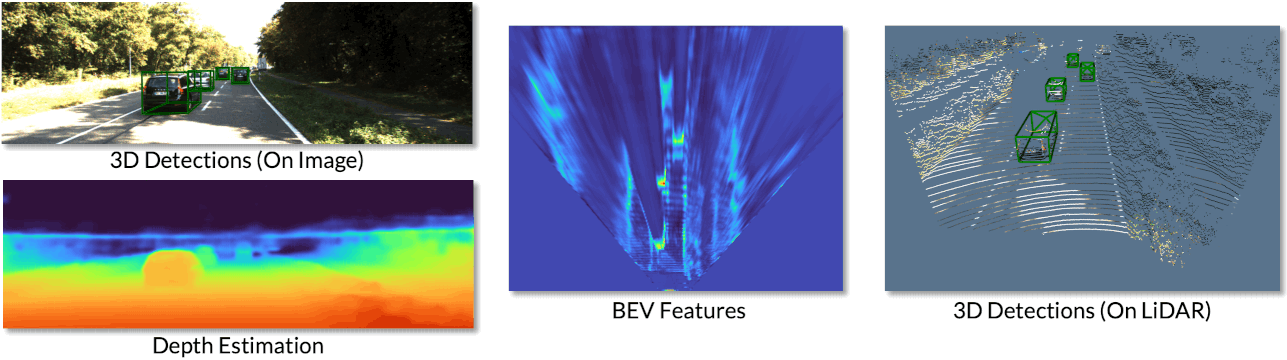
We can see the 3D detections on both the image and the LiDAR point cloud. We also visuialize the depth estimation results, where brighter colours indicate closer depths. We can visualize the BEV features in which objects can be accurately located.
Image Projection to 3D
We also compare the three approaches both by looking at detection peformance and by visualizing the BEV feature representation.
The Too Big approach results in smearing effects, which make accurate object localization challenging. The Too Small approach results in image features being placed in wrong locations where depth estimation is inaccurate. The Just Right approach allows for image information to be placed in the correct 3D locations while encoding depth estimation uncertainty.
Depth Distribution Uncertainty
Finally, we visualize the estimated depth distributions at each depth bin.
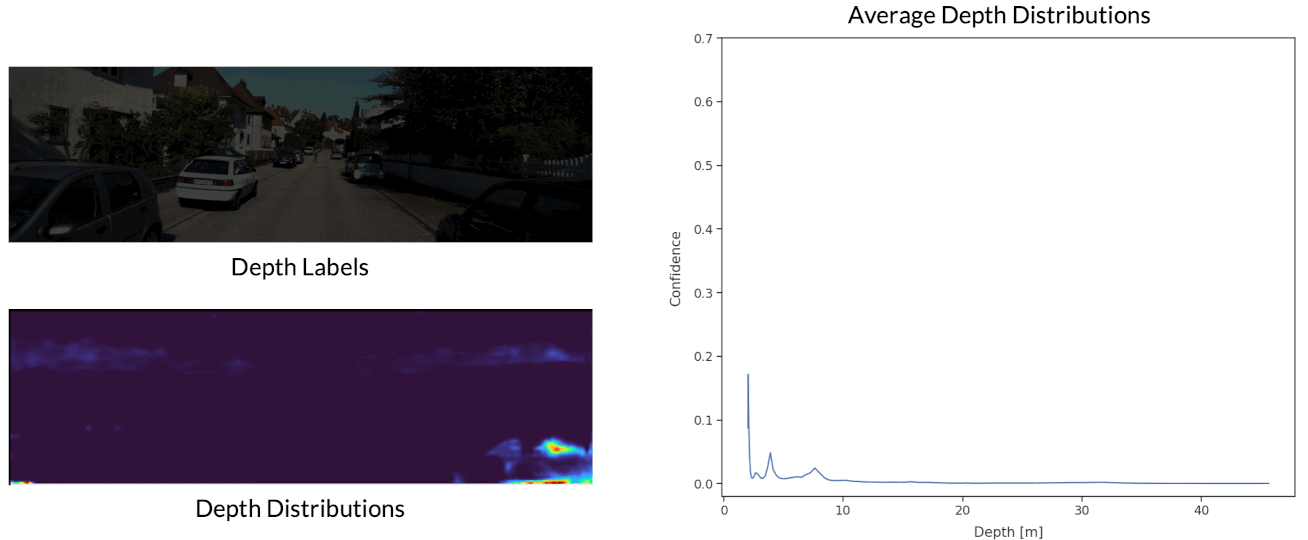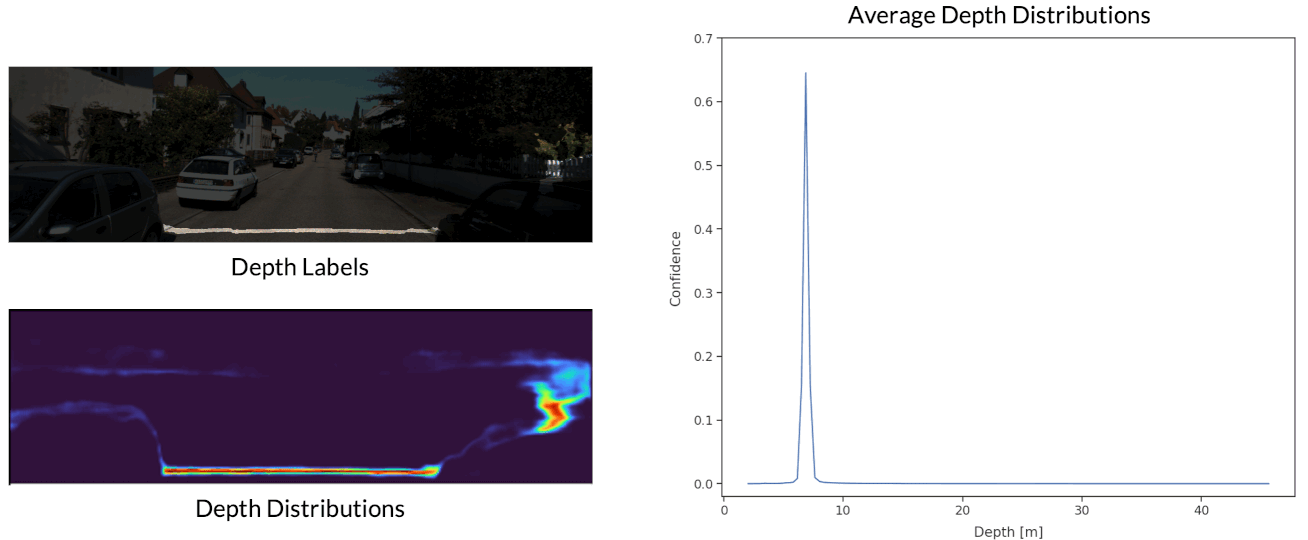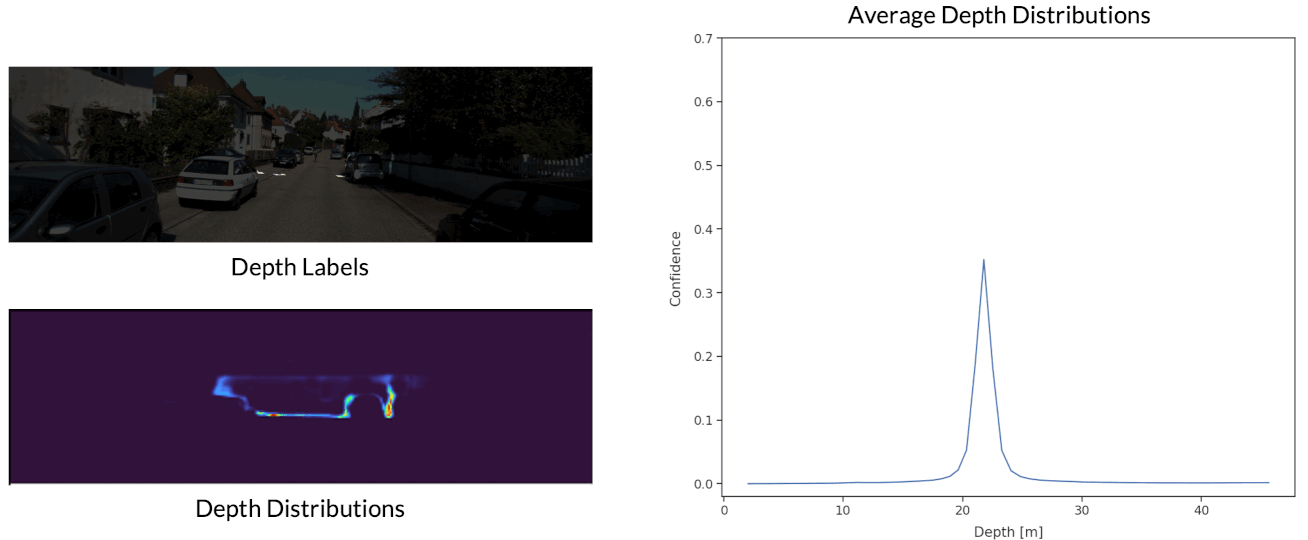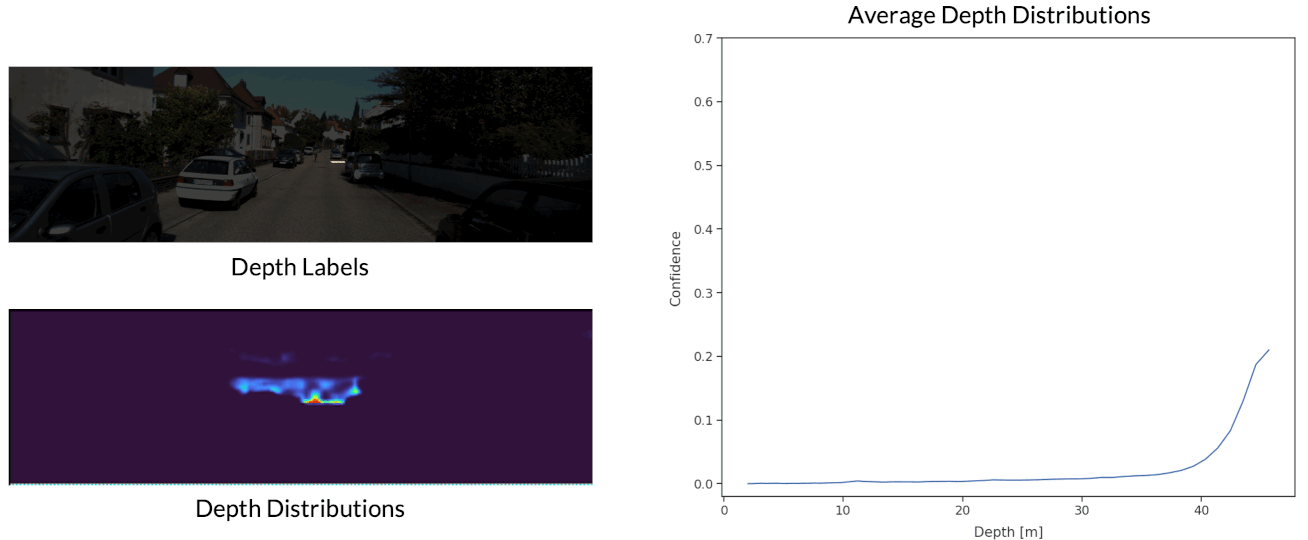
The depth distributions are shown by representing higher probabilties with brighter colours. The average depth distributions are also plotted for each depth bin. We observe that distributions become wider and shorter as a function of depth, which reflects the increased difficulty of depth estimation at long range.
Affiliations

